About ODCS, automation, and trust in a machine-driven data world with Dr. Simon Harrer.
Data mesh is often discussed as an organizational pattern, a cultural movement positioned against hyperscalers’ ready-made infrastructure, or a tooling challenge. Rarely is it examined as an interface problem.
And yet, many of the failures in large data-sharing organizations have little to do with team structure or platform maturity. They often stem from something far more mundane: expectations that exist only in people’s heads.
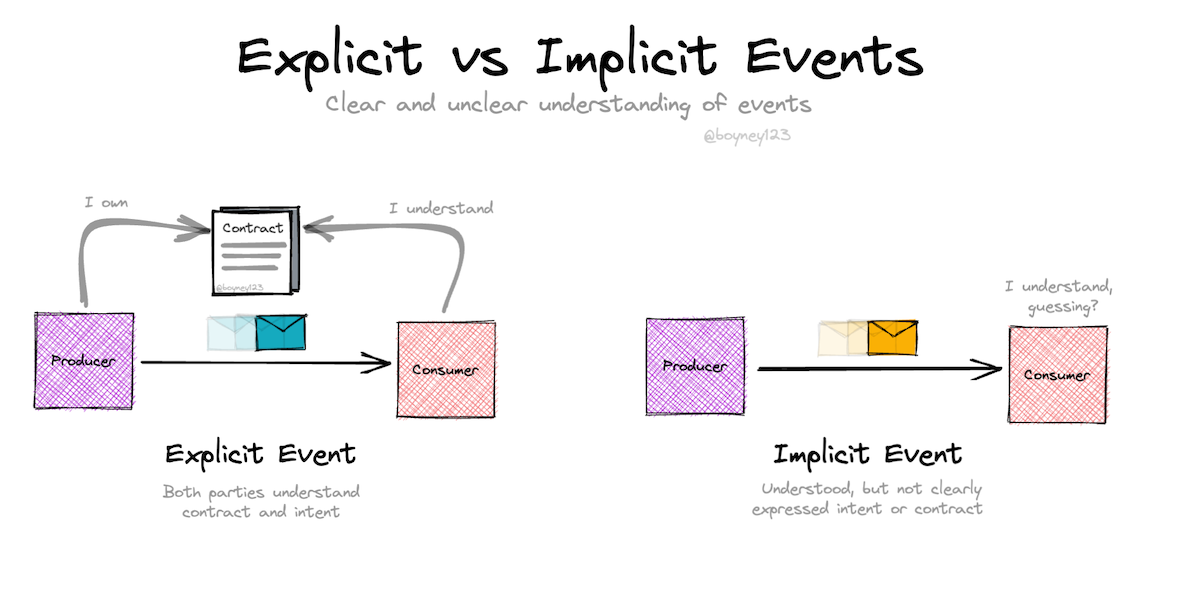
The question, then, is not how to organize data teams or which platform to choose, but how to make data interfaces explicit, trustworthy, and enforceable in practice. And that’s exactly what Simon Harrer along with his colleagues at Entropy Data has been working on for a while now.
But first, let’s get the record straight.
We first met in Munich during DATA Festival, as Simon was transitioning from senior data consultant into the role of CEO of a company he had been building with his friend Jochen Christ. Their work in data mesh had evolved from consulting into product, shape-shifting from Data Mesh Manager to Entropy Data, a platform centered on data products and data contracts, exposed through a self-service marketplace with governance and AI-driven capabilities.
And it seems that in the context of Entropy Data the original motivation behind data contracts was not governance or traditional data management, but a fundamental need to provide a solution as thorough and cohesive as an API specification in software engineering. Coming from software engineering, where APIs define what is offered, guaranteed, and what consumers are allowed to rely on, Simon and Jochen found it a tad difficult to accept. In data, this role never truly existed. Datasets were shared, but expectations around meaning, quality, usage, and ownership remained implicit, steadily eroding trust.
This is the gap Simon & Jochen set out to address, and the context in which his definition of a data contract becomes meaningful.
Obviously the ‘data contract’ concept existed way before Entropy Data tapped into it, but Simon’s interpretation of it was shaped strongly by software engineering practice. As said, to him, a data contract is analogous to an API specification: a complete description of everything a consumer needs to know in order to use the data safely.
This includes technical structure, but also much more than that. A data contract describes schema, quality expectations, SLAs, semantics, terms of use, ownership, and support channels. It acts as the source of truth for metadata about a dataset that is intended to be shared.
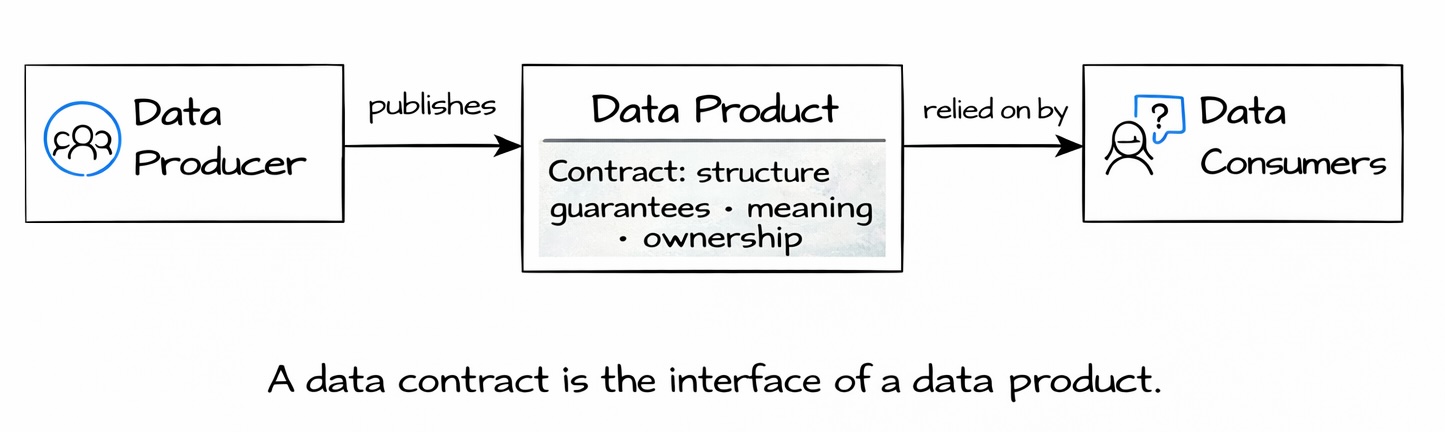
Importantly, Simon’s view of data contracts evolved over time. Initially, contracts were often thought of as producer-driven: defined by the team that owns the dataset and offered to consumers. While this remains a common and valid pattern, experience showed that it is not the only one. Contracts can also be consumer-driven. A consumer may define expectations for data they intend to rely on, effectively expressing what guarantees they require from a provider.
In our view, this shift is subtle but very important. It moves data contracts away from being a one-sided declaration and closer to being a collaboration mechanism, yet without losing their role as a technical artifact.
Specification without automation does not change behavior. This became clear very quickly.
The original Data Contract Specification defined how contracts should look, but it did not enforce them. And without enforcement, contracts risked becoming just another form of documentation. Simon had seen similar patterns before: metadata defined in Word documents or Excel spreadsheets that looked reasonable but were ultimately ignored.
This realization led directly to the creation of the Data Contract CLI. Automation was not an afterthought; it was essential. A contract only becomes meaningful when it can be validated automatically and when violations have real consequences.
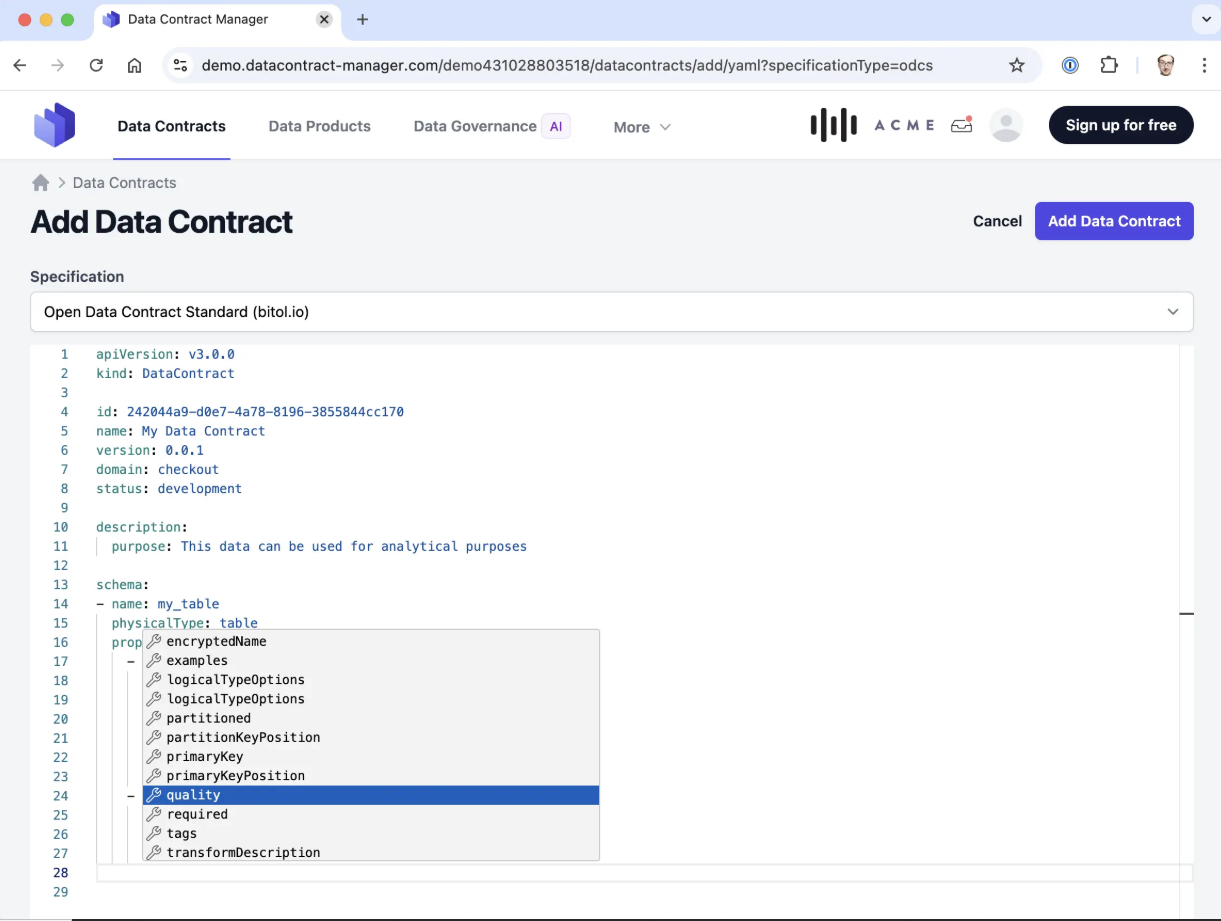
Later, when the Open Data Contract Standard (ODCS) at the Linux Foundation emerged, Simon and the team made a deliberate decision. Instead of competing standards, they deprecated their own specification and aligned fully with ODCS. Being fans of open standards, they chose to contribute to improving ODCS as part of the Technical Steering Committee of the bitol project, and added native support for it in the CLI.
The goal was not ownership of a format, but convergence around a shared, enforceable standard.
The decision to use a declarative, schema-driven format for data contracts was not arbitrary. OpenAPI (i.a.) served as a clear reference point. API specifications are written declaratively, validated against schemas, and treated as interfaces rather than code.
For Simon, this was an obvious choice. Data producers need to describe what they guarantee and what they expect from consumers. This is fundamentally declarative. Control flow, loops, and conditional logic do not add value here.
This is also why Simon is cautious about the use of DSLs for data pipelines. In well-contained cases, pipelines can sometimes be expressed declaratively with good results. At a larger scale, however, pipelines tend to grow in complexity, branching logic, and operational edge cases. In such environments, introducing a DSL may increase fragmentation and cognitive load rather than reducing it, especially in organizations that lack a strong platform team, well-defined architectural patterns, and mature infrastructure.
In other words, very few organizations are sufficiently prepared to sustain a custom pipeline DSL over time.
In contrast, using SQL for data quality checks aligns naturally with the declarative nature of data contracts. SQL is already widely understood, expressive enough for validation, and avoids introducing yet another abstraction layer that teams must learn and maintain.
When asked whether data contracts are primarily technical, collaborative, or governance-oriented, Simon’s answer is that they are all of these at once. And then some.
A data contract is a technical artifact, because it defines structure and guarantees in a machine-readable way.
It is a collaboration mechanism as well, because it becomes the explicit meeting point between producers and consumers. At that very line the expectations are discussed, negotiated, and made durable.
And last but not least, it is a governance control, because it allows rules and constraints to be enforced automatically rather than documented and hoped for.
But Simon pushes the definition further. A data contract is also part of the description of a data product, a key principle of data mesh paradigm, as it is exposed to the organization, effectively the product details page in a data marketplace. It captures not only what the data looks like, but what it means, how it can be used, what guarantees apply to it and finally how support and ownership are organized. Thus, essentially it becomes a single source of truth of metadata for a dataset to be shared in the organization.
This particular role becomes critical in an AI-driven environment. Data contracts provide the structured, explicit surface that allows autonomous systems to discover enterprise data, evaluate whether it is fit for a given purpose, request access, and ultimately consume it.
In that sense, data contracts are not just for humans trying to understand data, they are the foundation that allow machines to reason about data in a safe way.
And that’s a game changer.
Simon is explicit about one recurring mistake: trying to solve cultural problems with tooling. He has seen this pattern repeatedly. Not only in data, but earlier in Domain-Driven Design, Team Topologies, and DevOps transformations. In each case, organizations hoped that a new framework or platform would resolve deeper issues around ownership, collaboration, and responsibility. In practice, the tooling arrived first, while the underlying questions remained unanswered. Classic.
What helped Simon avoid this trap in the data mesh space was the path his work took. It did not begin with a product, but with consulting. Working closely with organizations exposed the real friction points of data sharing: unclear ownership, mismatched expectations between producers and consumers, and the lack of a shared language to describe what data actually guarantees.

Data contracts fit naturally into this perspective. They do not replace conversations; they structure them. A contract creates an explicit boundary around a shared dataset: what is being offered, under which guarantees, and under which constraints. That boundary becomes a concrete focal point where producers and consumers can align their expectations. Crucially, it is also a boundary that can later be enforced, once agreement exists. Without that prior alignment, enforcement merely hardens misunderstandings instead of resolving them.
This is where Simon’s pragmatic heuristic becomes important. Contract adoption, in his view, is not ideological and should never be universal by default. For new data use cases, defining the contract upfront creates immediate value: it forces early discussion of requirements and semantics and provides stability once pipelines are built. For existing data, however, he advises a different approach. Rather than attempting to put all data under contract, teams should start where the absence of explicit expectations already causes pain. Think: places where pipelines break frequently, where meanings require constant clarification, or where consumers repeatedly rely on assumptions that turn out to be false. In these cases, even a minimal contract can deliver quick value and evolve over time, without being perceived as another bureaucratic obligation.
This distinction is essential to how contracts support culture rather than undermine it. Introduced deliberately and in response to real problems, contracts reinforce trust and autonomy by making responsibilities explicit. Introduced indiscriminately, they are quickly experienced as governance theater. The difference is not the format of the contract or the sophistication of the tooling, but the context and intent behind its introduction.
Tooling, in Simon’s view, is therefore an amplifier, not a driver. Automation through linting, validation, and CI/CD integration ensures that agreements encoded in contracts are upheld consistently.
But the agreements must come first.
Without shared understanding and ownership, automation only enforces confusion. With them, data contracts become a mechanism that allows data culture to scale, without pretending that culture itself can be automated.
One of the most persistent misconceptions Simon encounters is rooted in the word “contract” itself. And honestly, “contract” might indeed be a little bit tight meaning-wise.
As a result, data contracts are frequently assumed to exist between a single data producer and a single data consumer. In practice, Simon sees them operating in a context of a data marketplace. A provider offers a dataset under a contract, and many consumers may discover that offering. Designing contracts as one-to-one agreements fundamentally limits their usefulness and undermines their role as stable, reusable data interfaces.
A second, closely related misconception is that data contracts are primarily technical artifacts. This perspective often comes from data engineers who focus on schema definitions and quality checks. While those aspects are essential, Simon stresses that they are only part of the picture. In practice, data contracts also encode terms of use, reference policies, clarify semantics, and define ownership and support responsibilities. Reducing contracts to schema validation strips them of the very context that allows consumers, be it human or machine, to use data safely and correctly.
Both misconceptions have similar consequences. They lead organizations to design contracts too narrowly, apply them too late, or dismiss them as bureaucratic overhead. In Simon’s experience, contracts only deliver their full value when they are treated as shared, marketplace-facing interfaces rather than bilateral technical agreements.
Simon’s guidance on contract-first versus data-first approaches is pragmatic rather than ideological.
For new projects, a contract-first approach provides immediate benefits. Defining the contract early forces teams to discuss requirements, semantics, quality expectations, and ownership before any pipelines are built. This upfront alignment often leads to significantly more stable systems and fewer downstream surprises, because consumers build against an explicit interface rather than inferred behavior.
For existing data usage, a data-first approach is usually unavoidable. However, Simon strongly advises against putting all existing data under contract at once. Doing so almost inevitably turns data contracts into perceived bureaucracy. Instead, organizations should focus on areas where problems are already visible: pipelines that break frequently, datasets that require constant clarification, or interfaces where misunderstandings repeatedly surface between producers and consumers.
In those cases, Simon recommends starting with a minimal viable contract. Even a contract that only captures schema, basic descriptions, examples, and clear ownership can quickly reduce friction and restore trust. Additional constraints, such as stricter quality checks, SLAs, or policy references, can then be added incrementally as the contract proves its value. Starting small not only accelerates adoption, but also ensures that data contracts are experienced as a practical stabilizing force rather than administrative overhead.
Data contracts are often described as backend-agnostic, but Simon is careful to draw a clear boundary around that claim. A contract describes data, and the shared language of data across systems is the relational model. As long as data can be expressed in terms of tables, columns, and constraints, a contract can provide a stable and meaningful interface. Regardless of whether the data is ultimately exposed via a data warehouse, object storage, a streaming platform, or an API.
That abstraction breaks down once data moves beyond the relational model. While logical types can be standardized at the contract level, physical representations cannot be inferred safely. Think situation when a data column may be stored as a text string in one system and as a numeric value in another.
The same logical field may require different physical types depending on the underlying technology, and those differences are not incidental. They encode performance characteristics, storage semantics, and access patterns that matter in practice. For this reason, data contracts must explicitly acknowledge physical types rather than attempting to hide them.
This has a direct consequence. Contracts are not trivially portable across platforms. Moving a data product from one technology to another often requires a corresponding change in the contract, even if the business meaning of the data remains unchanged. Simon treats this not as a flaw, but as a necessary constraint. Interfaces that pretend otherwise tend to become misleading.
Change in data systems is inevitable. And that is by all means fine.
What Simon and his team focus on is how that change reaches consumers. In many organizations, schema changes surface only after pipelines break, dashboards fail, or downstream teams start asking why their numbers no longer add up. By the time the issue becomes visible, trust has already been eroded.
Data contracts invert this dynamic by shifting the focus from reacting to breakage to managing evolution explicitly at the interface, before changes reach consumers.
A central insight here is that reliably detecting breaking changes is much harder than it appears. Some changes are straightforward to identify, a column removed or renamed, a type narrowed in an incompatible way. Others are far more subtle. A column may still exist and pass all structural checks, while its meaning has changed completely. A price column may shift from representing net values to gross values while the data type remains a floating point. Technically, nothing breaks - the schema is still valid. From a business perspective, however, the meaning of the data is fundamentally corrupted.
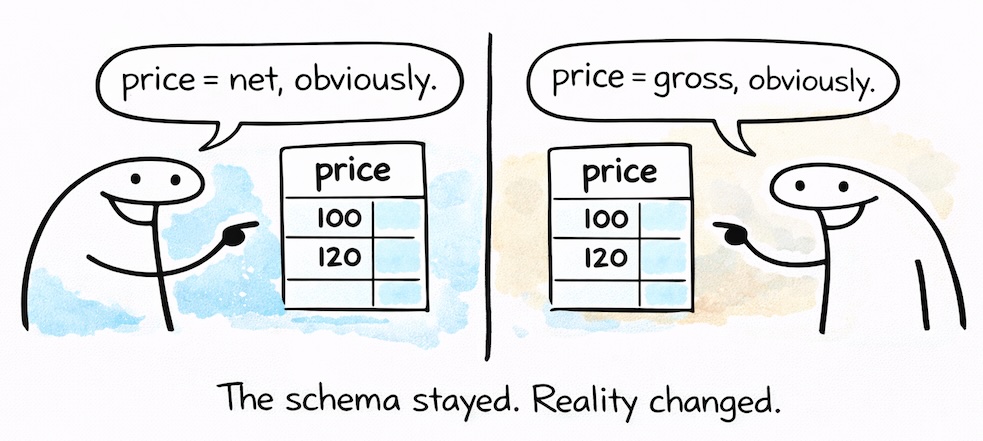
From Simon’s perspective, attempting to automatically classify all changes as breaking or non-breaking quickly runs into such limitations.
Instead, the contract becomes the point of truth. The primary question is not how the schema evolved, but whether the data still matches the contract. When it does, consumers can rely on the guarantees they were given. When it does not, the system must stop and force a decision. That decision can be made by a human, by an AI agent acting on defined rules, or by a combination of both, but it must be deliberate.
By anchoring schema evolution in the contract rather than in the underlying storage or pipeline code, Simon and the team try to reframe change as a controlled and transparent process.
Evolution remains continuous and expected, but its impact on consumers is negotiated and enforced at the interface. This is what allows data systems to evolve without repeatedly breaking trust, even as they scale across domains, teams, and technologies.
Coming from years of hands-on work as a data mesh consultant, Simon views data contracts not as an optional add-on, but as one of the critical success factors for making data mesh work in practice. In an environment where many autonomous teams produce and consume data across domain boundaries, implicit assumptions simply do not scale. Data is shared widely, but without explicit interfaces, consumers are left guessing what they can safely rely on.
In that sense, data contracts function as data APIs. They make explicit what a data product offers, under which guarantees, and for whom. Without such contracts, downstream teams cannot reliably build reports, dashboards, machine learning models, or applications on top of shared data. Every new use case requires re-validation, side conversations, and tribal knowledge.
This is also why data contracts play a key role in avoiding what Simon often refers to as “mesh theatre.” Many organizations invest heavily in mesh terminology, domain diagrams, and platform abstractions, yet struggle to deliver tangible value. Without concrete, enforceable interfaces, data mesh remains an architectural narrative rather than an operational reality.
Contracts change this dynamic. They protect specific datasets, establish clear expectations, and can be automated immediately through validation and CI/CD integration. As a result, they ground mesh principles in everyday engineering practice.
From Simon’s perspective, this also clarifies where contracts sit architecturally. Data contracts operate at the data product layer, not at the raw data asset layer. This distinction explains why traditional data catalogs so often failed. Attempting to govern all data assets centrally does not scale in large organizations. Governing shared data products, those that are intentionally exposed for consumption, is both realistic and effective. Contracts provide the boundary around those products, allowing governance to focus where it actually matters: on data that crosses team boundaries and carries organizational impact.
Seen this way, data contracts are not just compatible with data mesh; they are one of the mechanisms that allow its core promises, autonomy, scalability, and trust.
Add to this the fact that data contracts enable decentralized governance - yet another foundation of data mesh. Central teams can define global rules for what constitutes a good contract, but contracts themselves are created and owned by domain teams.
Automation is key here. Lightweight automated rules and checks integrated into CI/CD pipelines are often enough to drive high compliance. In contrast, governance rules defined only in wikis almost always fail.
Simon also sees a growing role for AI here. Instead of encoding all governance rules in rigid schemas, AI can monitor contracts in a marketplace against global rules expressed in natural language. This allows organizations to balance flexibility with continuous compliance once we all will be moving from “data” to “agentic” mesh.
When the conversation turns to AI, it seems to us that data contracts reach their natural point of leverage, especially in large, data-heavy enterprise environments.
AI agents are fundamentally data-hungry, but unlike humans, they cannot rely on intuition, informal knowledge, or hallway conversations to fill in the gaps. In decentralized data environments, this limitation becomes especially visible. As we explored in more detail in From Decentralized Data to Autonomous Agents, once data ownership and production are distributed across domains, agents have no shared mental model to fall back on. For them to operate safely and effectively, expectations must be explicit, machine-readable, and enforceable.This is precisely the problem space data contracts were designed to address.
In a contract-based data product marketplace, AI agents can operate without guesswork. By discovering and analyzing data contracts, an agent can identify which data products exist, what they represent, under which guarantees they are offered, and how they are meant to be accessed. Contract metadata provides the context needed to reason about semantics, quality, sensitivity, and usage constraints.
Based on that information, an agent can request access through the appropriate channels and later generate correct queries - joins, filters, and aggregations included - without relying on undocumented assumptions.
From Simon’s perspective, this makes AI agents not just another type of consumer, but most likely the primary consumers of data contracts in the future. Contracts already contain much of what agents need to operate responsibly: semantic descriptions, access rules, SLAs, quality expectations, and links to ownership and support. In that sense, data contracts do not need to be retrofitted for AI. If anything, they are already better suited to machines than to humans, because they encode expectations explicitly rather than implicitly.
Simon also sees a growing role for agents in the lifecycle of data contracts themselves. What one can think of here, is e.g. agents helping generate initial contracts from existing data, suggesting improvements, identifying missing metadata, or detecting patterns that indicate where contracts should be tightened or evolved. They may even act on behalf of consumers, requesting higher data quality or clearer guarantees.
This does not remove the need for ownership though. Even in highly autonomous setups, responsibility must remain clearly defined. A contract still needs an owner who is accountable for its guarantees, and in some cases, that owner may itself be an agent acting within explicitly defined boundaries.
Seen through this lens, data contracts become more than a governance tool or a collaboration artifact. They form the interface layer through which autonomous systems can safely interact with enterprise data.
As organizations move toward agentic architectures, Simon expects this role to become central: without reliable contracts, agents cannot reason about data; with them, they can operate at scale without eroding trust.
For us, the conclusion here seems straightforward.
Data contracts do not eliminate change, culture, or complexity. What they provide is something more fundamental: explicit, enforceable interfaces in a domain long dominated by implicit assumptions. In an increasingly agent-driven data landscape, that explicitness will become essential.
As our man of the hour puts it: “Data contracts are the key for the future, as they enable AI agents to discover business data.”