
On bottlenecks, autonomy, and the operating model behind data-heavy companies (with Xavier Gumara Rigol)
The promise of being “data-driven” rarely fails because organizations lack certain tools. It might fail across multiple points, but a large share of those failures can be traced back to the company operating model.
Xavier Gumara Rigol is a data and product leader who has recently written a book on treating data as a true product driver in modern organizations, out in April 2026. Our conversation started, as many do today, on LinkedIn. That exchange quickly evolved into a discussion about data mesh, data products, and the practical challenges of moving beyond centralized data teams. Certain patterns he has seen do repeat across different organizations and roles, so we proposed to dive deeper with this article.
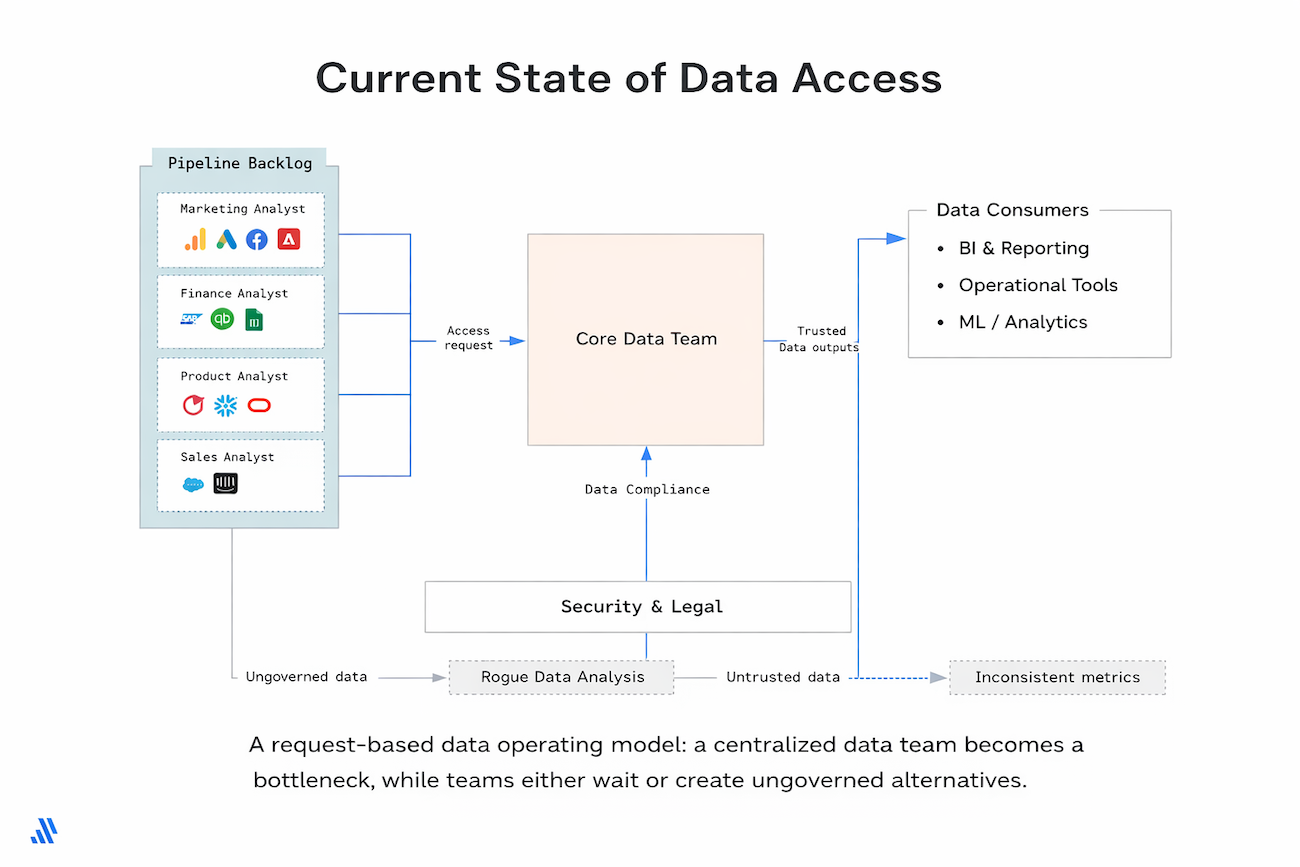
The motivation behind Xavier’s book, Data as a Product Driver, comes from watching this model quietly erode companies’ ability to use data at scale for analytics, machine learning, and AI. Centralized data teams become bottlenecks not because they lack competence, but because demand inevitably outgrows a request-based operating model. Meanwhile, product teams need autonomy: faster feedback loops, evidence-driven discovery, and the ability to act on insights without waiting in line.
Xavier documents that the most advanced organizations did not “adopt data mesh” or “implement data products” as a program. They iterated their way toward embedding data professionals inside cross-functional teams and treating data assets as products that enable outcomes.
That shift turns out to be far more disruptive than it sounds.
One of the clearest signals Xavier points to is how organizations measure success.
If success is expressed in dashboards created, models deployed, or pipelines shipped, the organization is optimizing for outputs. It may look productive, but it is not necessarily learning, improving products, or changing decisions. In many companies, being data-driven quietly becomes being dashboard-driven.
Outcome orientation changes the conversation. Teams stop asking what we should build? and start asking what measurable impact are we trying to create? That shift forces uncomfortable questions about ownership, quality, and trust. If a metric drives a decision, who owns its definition? Who ensures it stays correct over time? Who is accountable when it changes?
Those questions cannot be answered sustainably by a centralized data team acting as a service desk. The way the data team operates in an outcome-driven world needs to change.
Xavier is explicit that this transformation is rarely incremental. To drive outcomes, companies need to reorganize around problems instead of functions, which often implies a company-wide change: shifting from departments like engineering, design, marketing, and data toward business- or opportunity-oriented product teams.
Where does resistance show up first?
Not among individual contributors. Often not among product managers. It shows up among middle managers, engineering managers, and data science managers.
In the old model, these managers control priorities, approve decisions, and own delivery. In the new model, their people are embedded across multiple product teams, working on different initiatives under different product managers. The functional manager’s role shifts from directing work to coaching, setting standards, and developing people. That in itself requires slightly different skills in the ‘interpersonal skills’ department (emotional intelligence? oh no!).
For some managers, this shift opens space for a new role focused on coaching, quality standards, and capability building. For others, it removes the very mechanisms through which they previously exercised authority. Decision rights move to product teams, prioritization shifts to product managers, and day-to-day work is no longer coordinated through functional hierarchies.
A recurring theme in Xavier’s work is the distinction between decentralizing responsibility (output's function) and decentralizing ownership (outcome’s function).
Decentralizing responsibility often means asking teams to build dashboards, write queries, or maintain reports without giving them authority over the underlying data assets. They do the work, but they cannot decide on schema changes, quality thresholds, or access rules. This creates frustration and dependency – teams are accountable without being empowered.
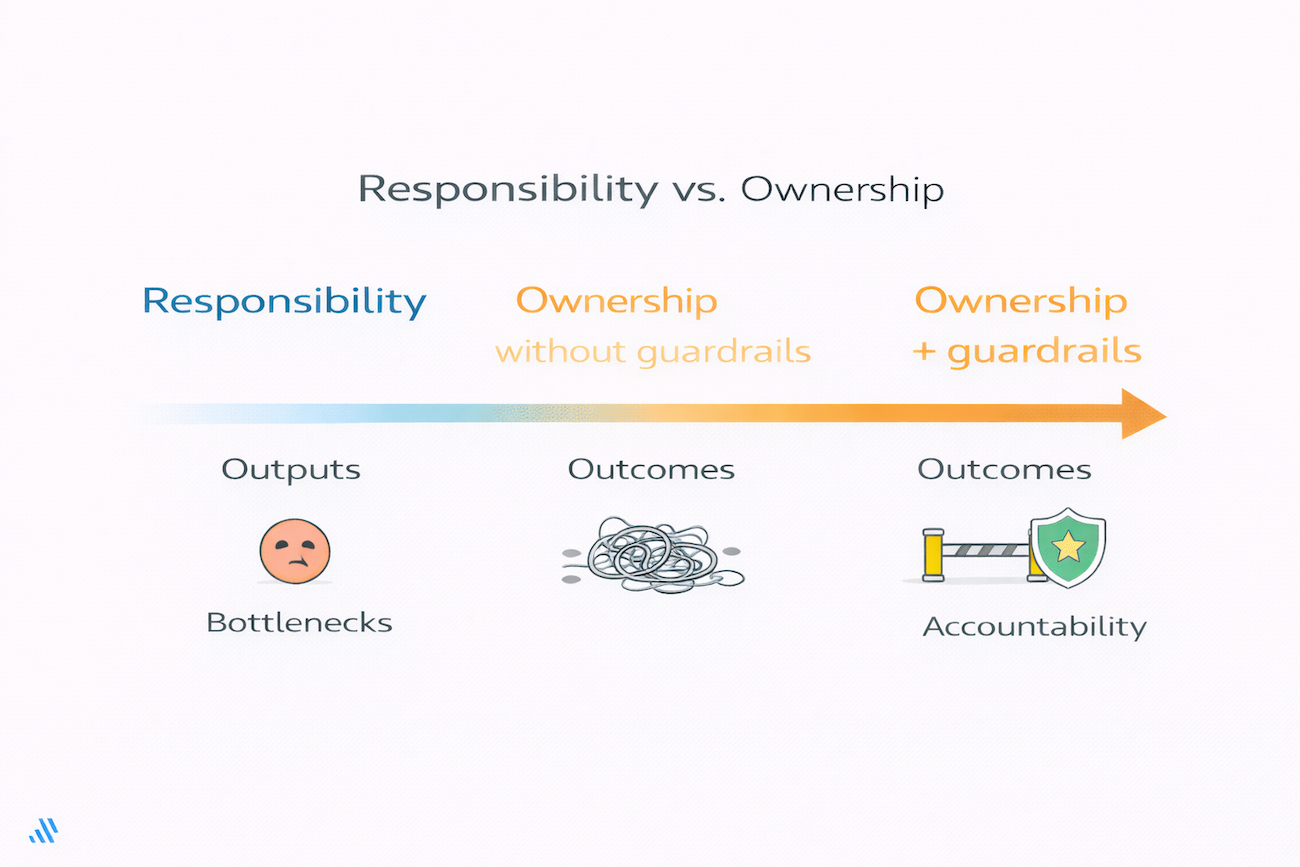
Decentralizing ownership, on the other hand, means transferring real authority and accountability for domain data to the teams closest to the business context. That transfer cannot happen blindly. Xavier points out several clear warning signs that an organization is not ready:
Ownership without properly defining capabilities and guardrails leads to chaos. Responsibility without ownership leads to bottlenecks. The solution is to transfer ownership gradually, starting with the most mature teams, providing enablement support from central teams, and establishing clear governance guardrails that protect the organization while empowering teams to operate independently within their domains.
When assessing maturity, Xavier consistently prioritizes one indicator above all others: reusable, discoverable data assets. Autonomy without reuse simply multiplies duplication:
“I've seen too many organizations where different teams build similar dashboards, duplicate datasets, or recreate the same algorithms simply because they can't discover what already exists. This waste frustrates me every time. Teams need to invest in building a solid layer of discoverable, reusable data assets first. Once you have this foundation, you can confidently decentralize.”
Xavier deliberately keeps the definition of a data product broad to avoid paralyzing debates about labels.
What matters is not whether something “qualifies” in theory, but whether it enables an end goal through the use of data. The real distinction emerges later, i.e. when products are no longer new.
In his book, Xavier starts from the classic product characteristics: a product must be valuable, viable, usable, and feasible.
But for data products, this is only the baseline. Data introduces a different class of risk. A data product can be technically usable and still misleading. It can be feasible to build and still erode trust over time.
That is why Xavier adds a second layer of requirements that apply specifically to the data itself. For a data product to be taken seriously, the data must be accurate, complete, timely, and trustworthy. It must scale without degrading performance, and security and privacy must be designed in from the start rather than bolted on later. These are not optional things, they are the conditions under which teams can rely on the product to make decisions.
And what separates durable data products from short-lived artifacts is what happens after the first release.
In practice, this shows up through a recurring set of features:
None of these traits are glamorous, but teams that skip them tend to accumulate portfolios of deployed dashboards, datasets, and models whose business impact is unknown and whose quality slowly degrades. Xavier refers to this as the “deploy and forget” mindset.
Durable data products survive because teams continue to care for them. Quality is monitored before users complain. Documentation evolves as usage changes. Ownership is clear when questions arise. Adoption is measured rather than assumed. And when a product no longer delivers value, it is retired deliberately instead of lingering as organizational noise.
This is where product thinking becomes real. Not in how fast something is built, but in how intentionally it is maintained — and eventually allowed to die.
Xavier’s view on product management is slightly (deliberately?:)) provocative because it challenges where accountability for data should live. It also quietly kills off a popular idea: the need for a dedicated “Data Product Manager” role.
In his model, data products belong with domain product managers inside cross-functional teams. The same people accountable for business outcomes are accountable for the data products that enable them. Simple.
Data products are not side artifacts owned by a separate data function, nor are they managed in parallel by a specialized role. They are part of the domain’s product strategy, governed by the same outcome-oriented thinking as any other product capability.
This shift has broader implications. As data becomes embedded across teams and data fluency permeates everyday decision-making, Xavier observes that dedicated “Head of Data” roles may evolve or, in mature organizations, even disappear. Data stops being represented by a single function and becomes something the organization simply operates with. Sounds too great to be possible & maybe it is not, but let’s dwell on it for a moment…
For product managers, the above distinction matters a lot. Owning data products does not mean owning everything. Domain PMs are accountable for data products that serve their specific outcomes, while platform teams retain ownership of the shared foundations no single domain should control. Accountability is distributed, but boundaries remain explicit.
Infrastructure matters, but Xavier consistently resists making it the center of the narrative.
His position is pragmatic: centralized capabilities should exist first.
Distribution along with the necessary technology should emerge when bottlenecks become visible, not as an ideological starting point. Platform teams should own shared infrastructure, cross-domain datasets, governance mechanisms, and self-service tooling. They should not own domain-specific analytics or product decisions.
But the general rule “platform teams succeed when they treat the platform itself as a product” does apply – big time! The cross-functional teams are the customers & the success is measured not in features shipped, but in time-to-insight, self-service rates, and reduced dependency.
Golden paths, clear ownership boundaries, and tight feedback loops matter more than elegant abstractions. Manual checks and simple documentation are often sufficient early on. Sophisticated platforms make sense only when multiple teams experience the same friction.
Xavier’s stance on data contracts is equally non-dogmatic. Contracts are not essential from day one in small but growing organizations. Teams should build first, feel the pain of broken dependencies, and learn where stability is actually required. Only then do contracts become valuable, not as formal governance artifacts, but as a way to document tribal knowledge and protect the most critical interfaces as organizations start to scale.
Governance follows the same logic. Xavier consistently argues for lightweight, focused structures: a small data governance council, short and regular meetings, a clearly defined scope. Governance-as-code where possible, but always in service of autonomy rather than control.
In practice, the failure modes are predictable. Data products without governance fragment into silos. Governance introduced without clear product ownership turns into a bottleneck. How to navigate, then?
Think this:
This is how balance can be achieved in practice. It’s not by designing the perfect model in advance, but by combining clear ownership, minimal but enforceable guardrails, and the willingness to adjust as real constraints emerge.
But what to do when…
For Xavier, generative AI does not introduce a new category of problems as much as it exposes old ones at an unprecedented speed. What changes is not whether organizations need good data foundations, but how quickly deficiencies become visible.
Across the data product lifecycle, the impact is uneven but very deep. During discovery, GenAI compresses cycles that used to take days or weeks. User research, interview transcripts, and qualitative feedback can be synthesized in hours, revealing patterns that previously required manual analysis. Early concepts are validated not through static mockups, but through working conversational demos, allowing teams to test ideas before committing to heavy implementation.
Delivery shifts just as dramatically. Instead of spending months collecting training data and building bespoke models, teams increasingly assemble context and craft prompts. The bottleneck moves from model training to context quality. Time-to-value shrinks from months to weeks (sometimes days) but only if the underlying data is well understood and accessible.
Maintenance changes the nature of operational work altogether. Instead of monitoring model drift and retraining schedules, teams track API costs, token consumption, and output quality through sampling. Prompts live in version control. These changes enable faster iteration, but they also introduce new disciplines around cost control, validation, and observability that many organizations are not yet prepared for.
In other words – rather than abstracting away data modeling, GenAI amplifies its importance. Organizations investing seriously in AI-native platforms quickly find themselves strengthening their foundational data architecture, not loosening it.
Looking forward, Xavier sees AI agents becoming active participants in data product work, not just passive tools. He already observes agents owning narrow workflows end-to-end: monitoring pipeline health, auto-fixing common failures, handling tier-one support questions. The emerging pattern is not teams replaced by AI, but teams augmented by many agents handling execution, monitoring, and routine decisions, while humans focus on judgment, creativity, and problem framing.
For data products specifically, this opens new possibilities. Agents can analyze usage patterns to propose optimized schemas, generate documentation automatically, detect unused or low-value assets, and even recommend retirement. The intent is not to replace human product thinking, but to expand what a small team can realistically own and maintain.
Xavier’s closing message is consistent and that’s also one of the major takeaways from his recent book: the transformation to decentralized only works when those two pillars move together:

Fix only one, and the system will most probably fail you.
The practical starting points? Modest, but powerful:
The ultimate goal is not to build more data products. It is to minimize what you build while maximizing impact.
Everything else – platforms, contracts, AI – will follow from that.