
In today’s data-driven world, businesses are collecting and processing massive amounts of data from various sources. While traditional data lakes provide a scalable solution for storing this data, they’re often plagued by issues around consistency, schema evolution, and query performance. These limitations can lead to costly inefficiencies, delayed insights, and even missed opportunities.
Apache Iceberg—a revolutionary open-source table format—is changing the game for data lakes. Built to address the critical challenges of data lake management, Iceberg enables organizations to achieve reliable, consistent, and performant data storage across different platforms and analytics engines. Rest assured we have a new standard in the making here, as all the majors are already investing to open up to it, and the trend will grow.
In this article, we’ll explore why traditional data lakes struggle, how Apache Iceberg solves these issues, and some practical SQL examples to help you get started.
Data lakes initially gained popularity because they allowed companies to store vast amounts of raw data, providing flexibility in data types and scalability. However, as data requirements grew, so did the limitations of traditional data lakes. The most significant challenges that we have seen when managing large datasets without a table format like Iceberg are as follows:
Traditional data lakes often lack transactional consistency, meaning that reads and writes can occur partially or out of sync. This inconsistency can lead to inaccurate or incomplete data, which in turn affects the quality of analytics and insights. For data-driven organizations, such inaccuracies can undermine decision-making and lead to costly mistakes.
Data schemas need to evolve over time to accommodate new business requirements and data sources. However, traditional data lakes often require substantial restructuring to support schema changes, which is time-consuming and resource-intensive. Such lack of flexibility really hinders the agility needed in today’s fast-paced, data-driven environments.
As datasets in data lakes grow, the demand for efficient querying increases. However, traditional data lakes rely on basic or manual partitioning methods that become inefficient at scale. This can result in slow query performance, high latency, and excessive resource usage, all of which impact the speed and responsiveness of data analytics.
Without robust versioning, data lakes make it difficult to track historical data states for purposes such as auditing, compliance, or troubleshooting. This lack of data version control complicates the ability to meet regulatory requirements, trace data lineage, and maintain a reliable history for key metrics. Additionally, without versioning, rollback capabilities are limited, making it challenging to recover from errors or unintended changes.
Apache Iceberg is an advanced table format specifically designed for handling large-scale analytics datasets in data lakes. Originally developed by Netflix and later adopted by the Apache Software Foundation, Iceberg brings together the scalability of data lakes and the consistency of data warehouses. By addressing data lake limitations directly, Iceberg allows companies to store and query data reliably, efficiently, and with flexibility for future growth.
Note: Iceberg’s open format makes it compatible with several major data processing engines, including Apache Spark, Flink, Dremio, and BigQuery, allowing organizations to work with their preferred analytics tools while benefiting from Iceberg’s robust data management capabilities.
Data consistency is crucial in analytics environments, especially when multiple users are accessing and updating the data. Iceberg supports ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring reliable reads and writes across concurrent processes. This transactional integrity is essential for maintaining accurate data, particularly in high-traffic applications.
Business Impact: Imagine an e-commerce company with transaction data from multiple regions. Without transactional consistency, data could be out of sync, leading to incorrect inventory levels or inaccurate sales reports. Iceberg ensures that all data reads and writes are completed reliably, preventing costly data errors.
Data schemas often need to change to accommodate new requirements. In many data lakes, schema changes require time-consuming data reorganization, which can lead to downtime and high operational costs. Iceberg, however, allows seamless schema evolution—users can add, remove, rename, update (widen the type of a column, struct field, map key, map value, or list element) or reorder (change the order of columns or fields in a nested struct) columns without modifying existing data, making it easy to adapt datasets as business needs evolve. Even though the SQL syntax for schema changes in Iceberg might look similar to systems like Apache Hive, Iceberg’s implementation stands out due to its efficiency and how it handles these changes at the metadata level, without rewriting or reorganizing existing data.

Example: The SQL syntax above may resemble commands in traditional systems, but Iceberg’s approach stands out due to its seamless handling of schema changes. Unlike Hive, which may require complex data rewrites or manual adjustments, Iceberg manages these changes purely at the metadata level. This means:
Partitioning is critical for optimizing query performance on large datasets. Traditional data lakes require manual partitioning, which must be explicitly specified in queries and difficult to maintain. Iceberg introduces hidden partitioning, a feature that automatically manages partitions behind the scenes to improve query performance without needing complex partition setups.
Sample table:

We have to explicitly add year, month, day columns.
When users query data, there are a few problems here:

New Apache Iceberg way:
We don’t have to add columns meant only for partitioning to a table (thus hidden partitioning). In the example below, we use the day() transformation to create partitions on the existing event_time column.
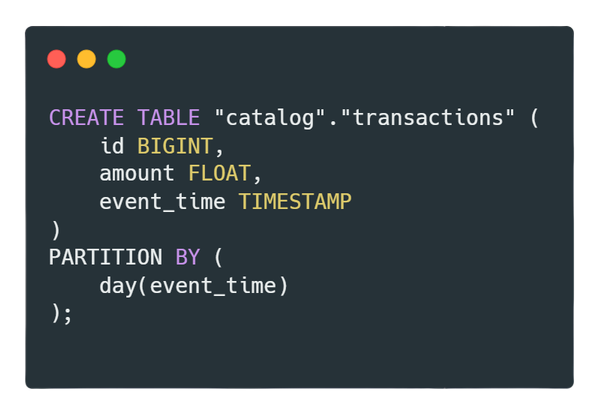
Users can naturally query the table without needing to remember to specify partitions explicitly to leverage querying only relevant data. Furthermore, there is no need to know what columns are used for partitioning data.

Technical insight: With hidden partitioning, Iceberg uses metadata to scan only relevant partitions, reducing query time and resource usage—enabling faster, more efficient data retrieval even in very large datasets. Also, it’s worth noting that other data warehouses, such as Snowflake, implement similar partitioning techniques. Snowflake’s micropartitions also improve efficiency by clustering data automatically, though Iceberg remains more partition-oriented and flexible, while Snowflake emphasizes automation in physical storage.
Iceberg’s time travel capability allows users to query previous snapshots of their data, which is particularly useful for audits, troubleshooting, and historical analysis. By creating snapshots with each data change, Iceberg enables users to access past data states without disrupting current processes.
To access data in a historical state, it can be done by specifying either:
To get a list of snapshots for an arbitrary table, the following command can be used:

After obtaining a snapshot ID:

To access data with a timestamp, the following code can be used:

Use case: In the finance industry, maintaining historical data is essential for regulatory compliance. With time travel, a financial institution can query the data as it existed on a particular date, simplifying audits and regulatory reporting. This concept of time travel or snapshotting is widely used across platforms, such as MapR File System, Snowflake, and BigQuery, highlighting its importance in data management and compliance.
Apache Iceberg’s features make it a powerful solution for large-scale data management, enabling organizations to:
These technical capabilities set Iceberg apart from traditional data lake architectures, making it a solid foundation for organizations looking to scale their data infrastructure.
Apache Iceberg is transforming data lake management by bringing the consistency and reliability of databases to large-scale data environments. From what we have seen thus far, it is just spot-on. But how does it perform across different platforms like BigQuery, Snowflake, and Dremio? And how do these implementations differ in practice?
In future articles, we’ll dive deeper into Iceberg’s integrations with various platforms, comparing their strengths, trade-offs, and unique capabilities. Whether you’re exploring Iceberg for your organization or simply want to stay updated on modern data solutions, follow along to learn how Iceberg can enhance your data strategy.
At insightify.io, we design scalable architectures for data-intensive applications, with a focus on data governance and efficient data lake management. Unlock the power of your data with Insightify.